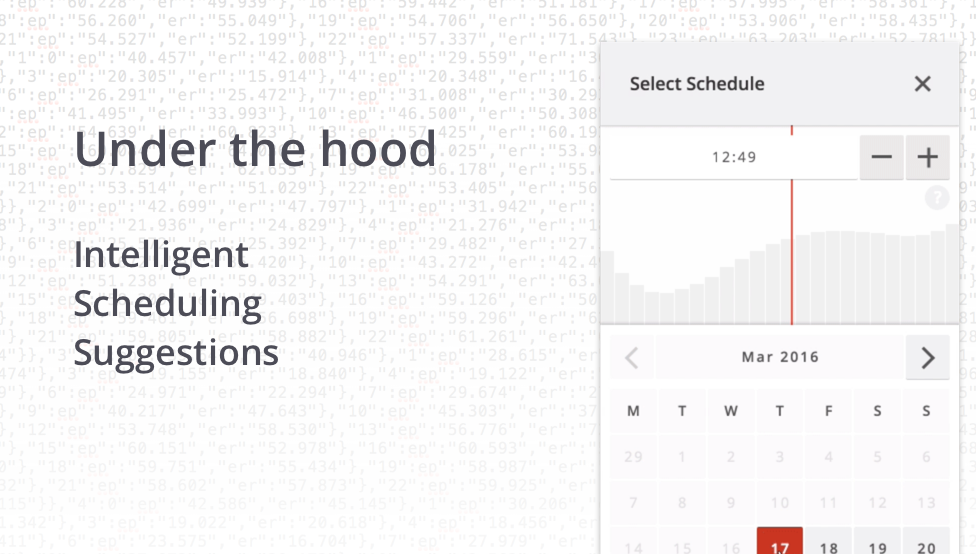
We recently released a new feature that helps you pick the best time to schedule your content. Since then we’ve had a lot of questions on how we were able to do this, so in this blog post, we’ll dive into some of the technology behind this feature.
Data + Machine Learning = Insights
Machine learning is immensely popular these days. Computing power and hardware have become advanced enough to allow techniques such as Deep Learning to reach new limits. This is the kind of technology that powers Siri, self-driving cars and recently beat a top Go player. In KAWO we’ve only recently started utilizing Machine Learning, with which we plan to introduce a series of new features to help you make intelligent, data-driven decisions. Machine Learning commonly entails feeding lots of training data into an algorithm to create a prediction model. The accuracy of the model is determined by the quantity and quality of the data in combination with the chosen algorithm.
Our plan
We wanted to provide a graph that predicts the likelihood of getting engagement by hour of day. The graph would have to be specific for the selected day of the week since people have different behavioral patterns on different days. A typical example would be that people would check their Weibo on different times on the weekend as opposed to weekdays.
Another problem we ran into was that on some occasions, we wouldn’t have enough data to work with, for instance when a new client starts using KAWO, or when an account hasn’t been very active. Predictions wouldn’t be accurate without sufficient data. We chose to use data of similar accounts and group them together to show what is working well for accounts similar to yours.

1. Getting data
Luckily, our systems are already tracking hundreds of accounts in dozens of industries across Chinese Social media; it’s the same engine that powers our competitor intelligence feature. Our database contains all post data, fan growth and engagement by the hour for each account.
2. Preprocessing
This step is often undervalued but surely just as important as the other steps. Raw data often needs to be reviewed and ‘cleansed’, even more so when it involves user generated text. In our case, it means identifying accounts and posts that could have a negative impact on the quality of our data.
For instance, some accounts post very infrequent and always receive massive engagement no matter what time they post. Normal distribution is a great way to get rid of anomalies. Another example would be getting rid of ‘contest’ posts as they also receive high amounts of engagement, which has little to do with the time posted. Excluding these cases from our training set has greatly improved the accuracy of our prediction model.
3. Choosing the right algorithm(s)
To group the accounts we’ve chosen to cluster the accounts into 27 clusters by K-means clustering with average posts, engagement and followers as features. For each cluster for each day of the week, we apply polynomial regression to fit a nonlinear model to the training data, which creates the prediction line.

The result
When you click the schedule button when creating or editing a Weibo post, the system quickly predicts which cluster your brand belongs to and shows the prediction data for that cluster and the selected day.
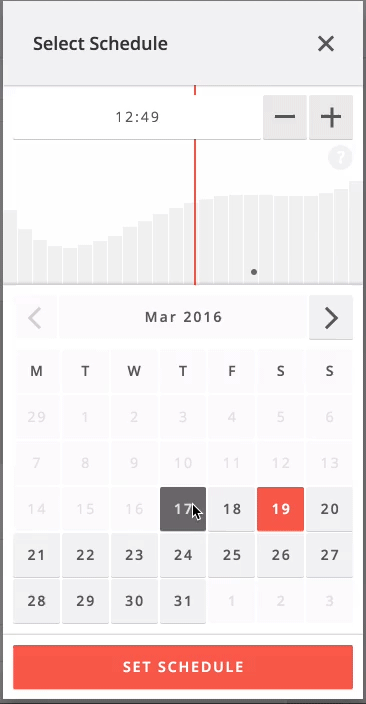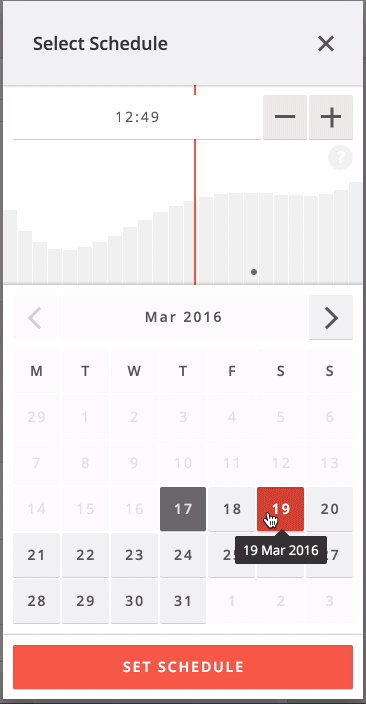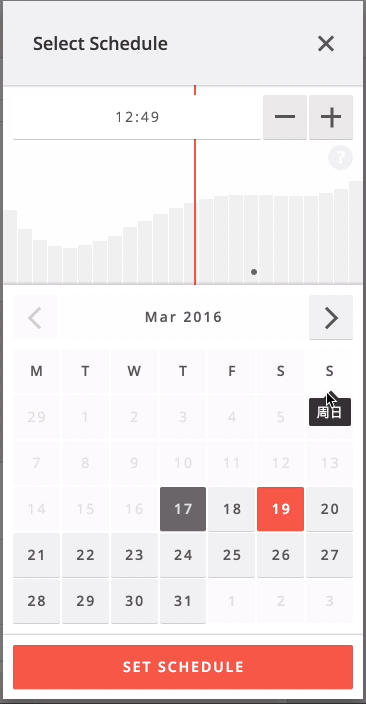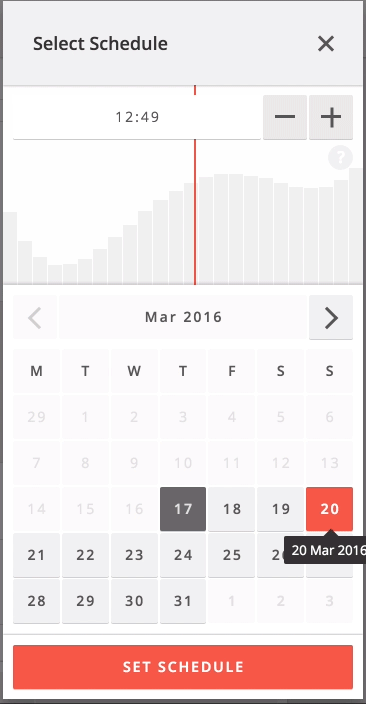
Next steps
Accuracy is higher than 60% for the majority of clusters and we’ve already found a couple of ways to improve it. We’re looking into different ways to cluster accounts based on content topics and/or the shape of an account’s engagement over time. We also plan to include more of your brand’s data to make predictions even more tailored towards your brand.
We’re always looking for ways to improve your KAWO experience. If you have any questions, ideas or other feedback, please don’t hesitate to contact us.
KAWO is hiring! Have a look at our jobs page for a list of open positions.